Two Whys Behind Positional Encoding in Transformers
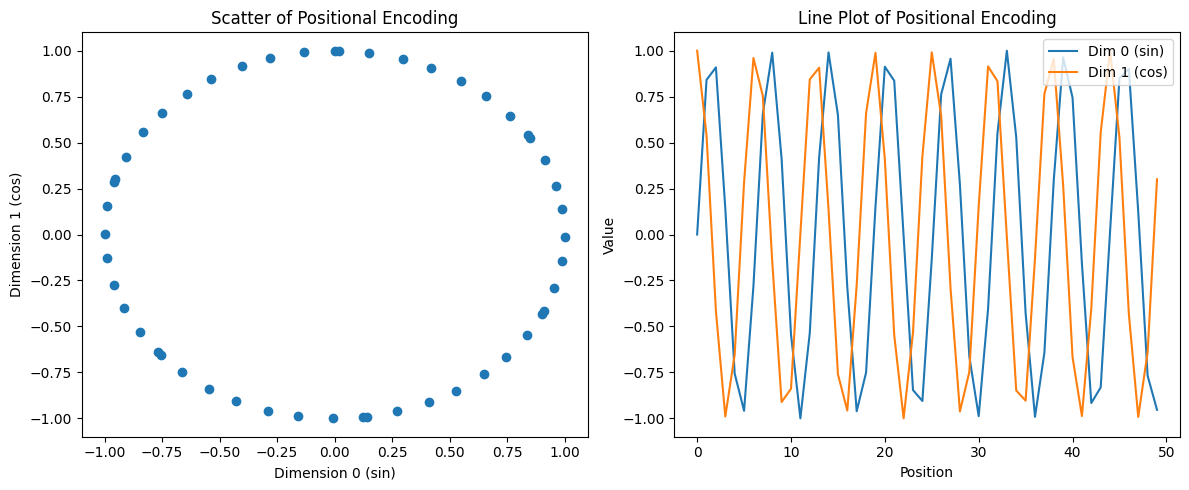
First Why: Why do we need positional encoding in word embeddings instead of passing the embedding vectors directly to the attention mechanism? Second Why: Why do we use sinusoidal functio...
First Why: Why do we need positional encoding in word embeddings instead of passing the embedding vectors directly to the attention mechanism? Second Why: Why do we use sinusoidal functio...
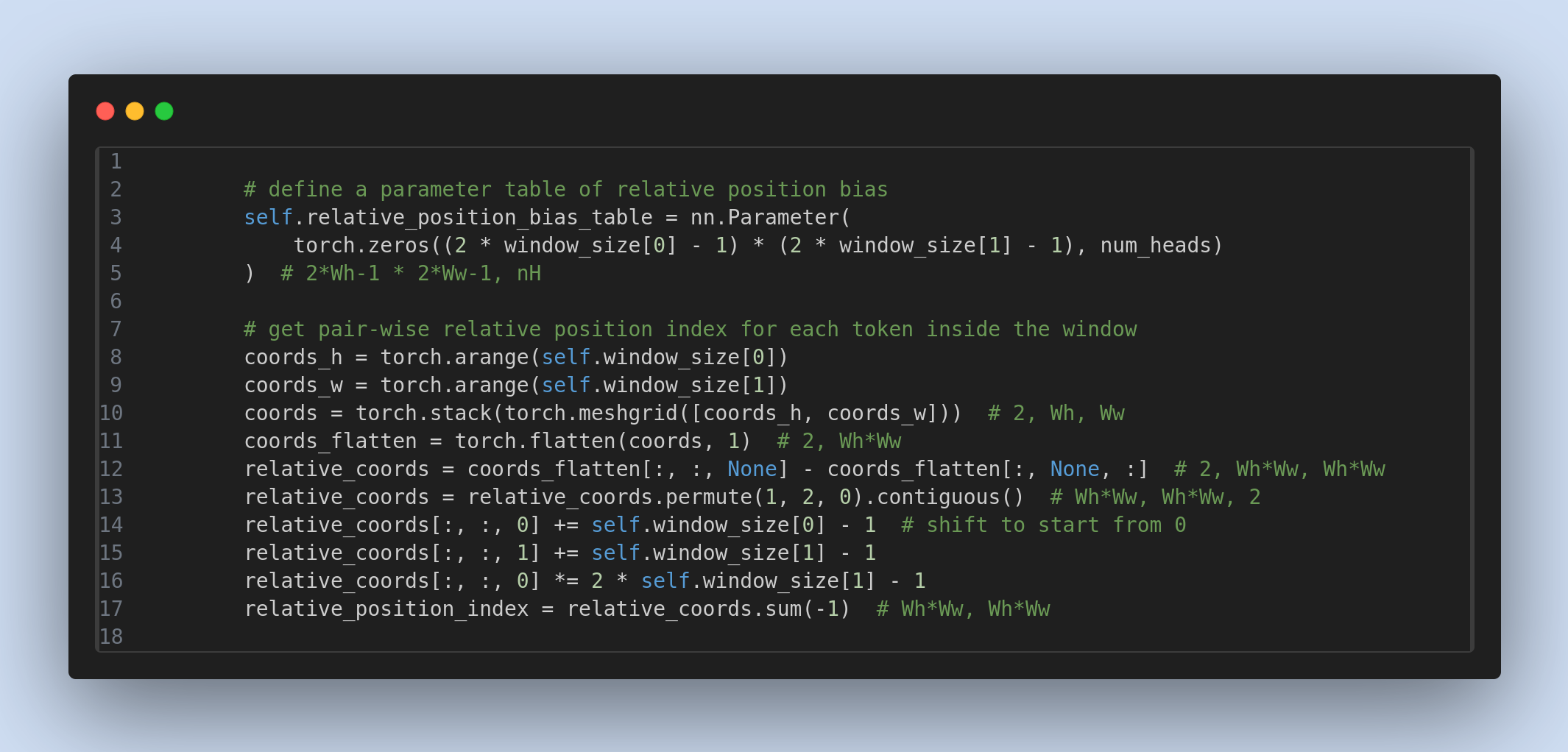
Relative position bias, introduced in the Swin Transformer research paper, enhances the Absolute Positional Encoding mechanism by effectively capturing positional information within image patches. ...
.jpg)
Demystify the embedding layer in NLP, which transforms tokens - whether words, subwords, or characters - into dense vectors.

This article series is divided into two parts. In the first part, I will explain the basics of Class Activation Maps (CAM) and how they are calculated. In the second part, I will delve into the w...